シェーダーコードの作成で、よく躓きがちなのはバッファの要素のアライメントがずれる、という点でしょう。たとえばユニフォームバッファで要素を追加して、C++側とGLSL側、他方でその修正を忘れるとすぐにおかしな状態に突入します。これはまだ気付けるとして、暗黙のアライメント制約によってアクセスがずれてしまうケース、これがこの記事で取り上げたい話題のベースです。
ユニフォームバッファから確認
ユニフォームバッファやストレージバッファの各要素について、一般的に使用されるのは std140 やstd430のレイアウト指定です。以下のような構造体で示されるバッファブロックを考えてみます。
uniform SceneConstants {
vec3 toLightDir;
float intensity;
vec3 ambientColor;
vec3 specularColor;
float dataList[4];
} gConstants;std140 の場合
std140では、基本的に1要素が占めるバイトサイズのアライメントを要求します。floatやintなら4バイト、vec2なら8バイトです。例外的なのがvec3で、12バイトのアライメントではなく、16バイトアライメントになっています。mat3 も例外的で、16バイトアライメントで、48バイト領域を占めます。
配列は厄介です。C++では上記の場合では隙間なくfloatデータがメモリ上に並びますが、シェーダー上では、1要素が16バイトアライメントが必要です。そのため、素直なデータ渡しをすると、途中のデータが歯抜けになった状態となります。
このデータの場合、各要素の先頭からのオフセットを求めると以下のようになります。
| toLightDir | 0 |
| intensity | 16 |
| ambientColor | 32 |
| specularColor | 48 |
| dataList | 64 |
| フィールド要素 | 先頭からのオフセットバイト |
std430の場合
Vulkan 1.2からは VK_KHR_uniform_buffer_standard_layout がコア機能に昇格したことで、 std430 レイアウトが ユニフォームバッファで使うことが可能となりました。それまでは、このレイアウトはストレージバッファ(SSBO) でのみ使うことができました。
std430 ではアライメント制約が少し緩和されています。vec3のアライメントは変化しないものの、float配列についてはC++と同じように隙間なく詰められたデータにアクセスが可能となります。
| toLightDir | 0 |
| intensity | 16 |
| ambientColor | 32 |
| specularColor | 48 |
| dataList | 60 |
| フィールド要素 | 先頭からのオフセットバイト |
ストレージバッファのアライメント
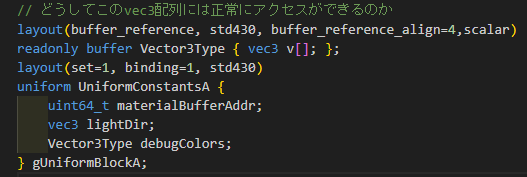
さて本題です。ストレージバッファを用いて、デバイスアドレス拡張を利用しているときに、vec3 要素が隙間なく並んでいるデータ構造にアクセスできていることに気付きました。例えば、以下のような宣言・定義があったとします。
layout(buffer_reference, std430, buffer_reference_align=4,scalar)
readonly buffer Vector3Type { vec3 v[]; };
layout(set=1, binding=1, std430)
uniform UniformConstantsA {
uint64_t materialBufferAddr;
vec3 lightDir;
Vector3Type debugColors; // C++からは64bitアドレスでデータを書き込む
} gUniformBlockA;
このとき、debugColors.v[ index ]; のようなアクセスをすると、確かに vec3 として期待するデータにアクセスできました。これまでのアライメント制約からすると不思議な点です。
そこで、どのようなコードが出力されたのかを開いてみましょう。少し抜粋したものが以下の通りです。確かに1要素のサイズを認識しているようです (ArrayStride 12)。
OpMemberDecorate %UniformConstantsA 0 Offset 0
OpMemberDecorate %UniformConstantsA 1 Offset 16
OpMemberDecorate %UniformConstantsA 2 Offset 32
OpDecorate %UniformConstantsA Block
OpDecorate %_runtimearr_v3float ArrayStride 12
OpMemberDecorate %Vector3Type 0 NonWritable
OpMemberDecorate %Vector3Type 0 Offset 0
OpDecorate %Vector3Type Block次に、要素アクセスのコードを追加して同様にSPIR-Vレベルのコードを出力してみます。ここでは要素17にアクセスしたものとします。
%56 = OpAccessChain %_ptr_Uniform__ptr_PhysicalStorageBuffer_Vector3Type %gUniformBlockA %int_2
%57 = OpLoad %_ptr_PhysicalStorageBuffer_Vector3Type %56
%60 = OpAccessChain %_ptr_PhysicalStorageBuffer_v3float %57 %int_0 %int_17
%61 = OpLoad %v3float %60 Aligned 4
OpStore %v %61このコードを見ると、与えられたアドレス情報に対して、 “17” を加算して、そのアドレスからデータ(%v3float) をロードするコードとなっています。このようにしてアドレスを計算、それからロードという方法を採用しているようです。なおここで表示しているコードの冒頭は、アドレスキャスト分も含まれているようです。
コメント